ブック task07.xlsx の 来店者 シートは各行が来店者の情報に対応しているデータが入っている。
1. 入店重量と購入重量を使って、お店を出るときの重量を新しい列(予想退店重量)に計算しなさい。
2. 予想退店重量と、実際の退店重量を使ってお店を出るときの重量の予想と実際の差を新しい列(重量差)に計算しなさい。ただし、お店を出るときの重量が予想よりも重い場合はプラス、軽い場合はマイナスとなるように計算すること。
例題1. 仮説から期待される性質を予想し、どうやったらチェックできるか考える
トイレに行った場合にありそうなこと
1の性質(滞在時間が長くなる)は、トイレ行かない人よりも余計なことをするので平均的には長くなっても不思議はない気がする。
2.の性質(大と小で減る重さが違う)のは、排泄量が違うので当たり前な気がする。この場合は、「トイレっぽく減っている人」の重量減が、大と小に対応する2つの重さを中心に集まっているかどうかをチェックするとわかるんじゃないかな。
3の性質(大と小で時間が違う)は、多分大の方が時間が長いだろう。これは1の性質と組み合わせて「大っぽい重量で時間が長い人と、小っぽい重量で時間が短い人」といえそうなら、重量が減っている人はトイレという強い根拠になりそう。
練習問題1
練習問題2(☆)
AKB48総選挙の結果(task07.xlsxブックのAKB48シートに入っている)から、仮説「前回の総選挙で順位が高かった人はその次の回も高い」をチェックする方法を考えなさい。
例題2 お店での滞在時間を計算してみる
Step 1. 新しい列を挿入して、列タイトルに滞在時間とつけておく
Step 2滞在時間 に 退店時刻−入店時刻を計算する計算式を入れる。
できあがりはこんな感じ。なんか計算できているようだが、1900年1月0日などという意味不明の日付がセットになっているのがいまひとつ変。
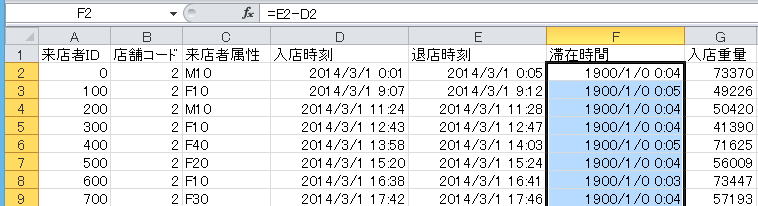
Step3表示形式を「標準」にしてみる
変な書式(日付)がついているから結果が変なのかもしれない。そこで表示形式を「標準」にしてみよう。できあがりはこんな感じ。

実際のデータとしては、0.00312317などというずいぶん小さな値が入っている。これが退店時刻−入店時刻の結果になっているので滞在時間のはず。
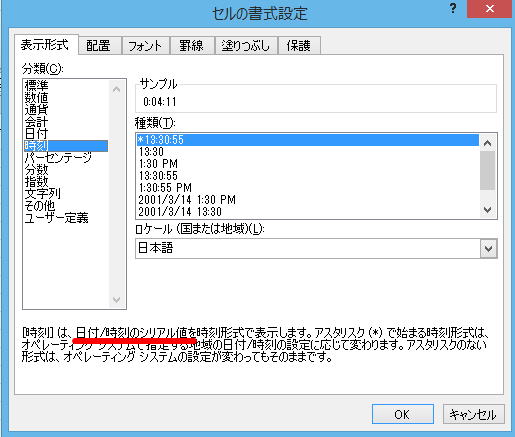
Step 4 表示形式を「時刻」にしてみる
セルの書式設定ダイアログから「時刻」を選ぶ。ちょっと気になる「シリアル値」ということばが入っているけど、ここでは気にしない。
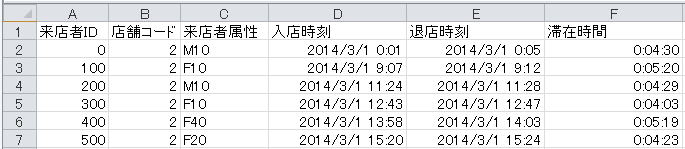
できあがりはこんな感じ。なるほど、時刻表示にしたら、分、秒単位の表示になった。来店者IDが0の人の滞在時間は4分30秒。分単位の表示で 0:01に入店して0:05に退店しているから、だいたいこんなもんだろう。
Tips シリアル値ってなに?
Excelでは、上述のダイアログにも出てきたように、「シリアル値(serial value)」とよばれる形式で日付や時刻の情報を扱っている。これは、1900年1月1日 00:00:00を1とする値で、1日が1に相当し、1時間は 1/24で約0.042、1分は1/(24*60)で約0.000694に相当する。
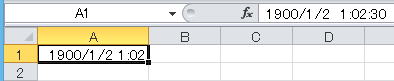
例 1900年1月2日 01:02:00 を表すシリアル値は、2日なので1日分増えて +1、1時間の増加分が約0.042、2分の増加分が 0.000694*2で合計すると約2.0434くらいになるはず。実際にExcelにこの値を入力して、表示形式を日付に変えると以下のようになる。(正確な値はもう少し小さいので、秒のレベルで誤差がでている)。
シリアル値利用上の注意
Tips Excelは内部的にどうやって日付や時刻を扱っているのか
練習問題3
練習問題4(☆☆)
例題3. お店への滞在時間と重量差の集計をやってみる
Step 1 必要な列を来店者シートから選択して、ピボットテーブルを作成する。
上述の通り、行ラベル(表側)に滞在時間、列ラベル(表頭)に重量差をとって作成してみる。できあがりはこんな感じ。行ラベルや列ラベルにやたら細かい数字が沢山入っていて、全然集計になっていないためデータが見えなくなっている。
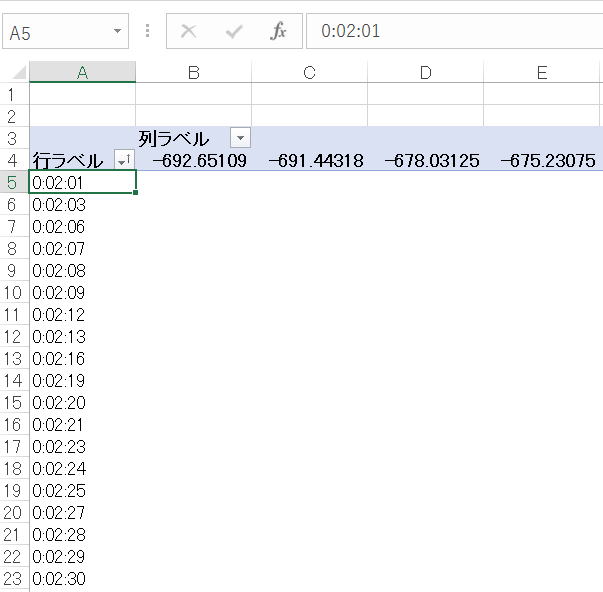
Step 2 滞在時間データのグループ化を行う
Excelのピボットテーブルには、こういうときのためデータをまとめてくれる「グループ化」という機能があるので使ってみよう。
(1)まとめたいデータのどれかをクリックしてアクティブセルにする。下図では、A5セルを選択している
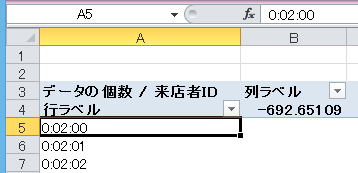
(2)ピボットテーブルツール-分析-グループから![]() (フィールドのグループ化)をクリックすると、以下のような「グループ化」ダイアログが表示される。
(フィールドのグループ化)をクリックすると、以下のような「グループ化」ダイアログが表示される。
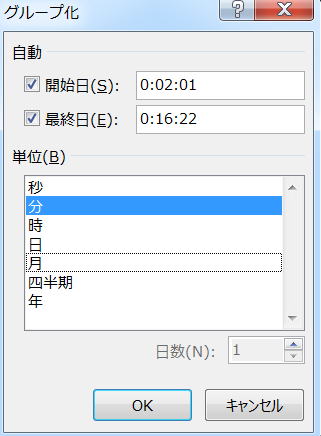
今回はシリアル値が入っているデータをグループフィールドに使っているので、Excel側で自動的に日付・時刻データだと思って扱ってくれている。Excelは表示形式の設定でこのへんを判断しているようなので、適切な表示形式を設定することは大事。
開始日、最終日はそれぞれ最小のデータと最大のデータを表している。お店にいる時間が一番短かったひとは2分、一番長かった人は16分14秒。これくらいなら、分単位で集計してもよさそうなので、単位として「分」をクリックしてOKをクリック。
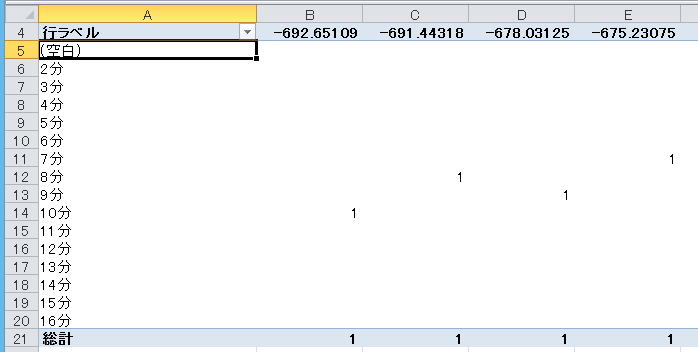
(3)分単位でグループ化すると、行ラベル(表側)が分単位にまとめられた。でも列ラベル(表頭)はちょっとまだダメ。
Step 3 重量差のグループ化を行う
Step2が終わったところでよくわからなかったのは、重量差がグループ化されていなかったから。そこでここもグループ化してみよう。手順はほぼ同じ。
(1)列ラベルを1つ選んでアクティブセルにする
ここではB4セルを選んでみた
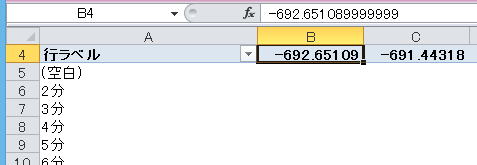
(2)ピボットテーブルツール-分析-グループから![]() (フィールドのグループ化)をクリックすると、以下のような「グループ化」ダイアログが表示される。
(フィールドのグループ化)をクリックすると、以下のような「グループ化」ダイアログが表示される。
日付・時刻データの時はExcel側でいろんな候補をだしてくれていたけれど、単なる数値の場合はずいぶんすっきりしている。「先頭の値」というのがデータの最小値、「末尾の値」というのが最大値、「単位」というのが、グループの幅になる。
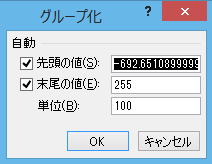
(3)先頭の値と単位を指定する
Excelが提案してきたままだと、-692.6510899999≦x<-592.65108999999みたいな(人間にとって)わかりづらい区間に分割されてしまうので、「先頭の値」だけ指定しておこう。前に万引きの話をしたとき、0近辺に誤差が沢山あることがわかったので、-50〜50くらいの区間ができるように、先頭の値を -650にしてみる。
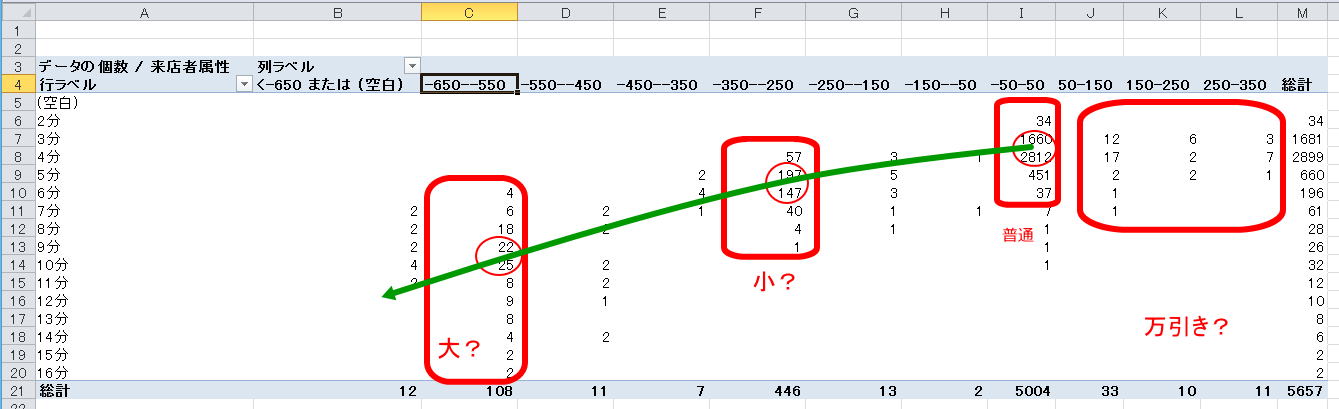
できあがりはこんな感じ。なるほど-650〜-660gのあたりに108人、-350〜-250gのあたりに446人集まっていて、それぞれ大と小に対応していそうだ。滞在時間も大の方が小より長い。どうやら「重さが減っている人はトイレを使っているらしい」という仮説はそれっぽい。
練習問題5 区間幅を変えてみる
例題3では「何となくいい感じの分刻みと100g刻み」のグループ化で上手くいったような気がするが、もっと刻みを細かくしたり荒くしたり、先頭の値を変えたり(区間の位置を変えたり)したらどうなるだろうか?
※このへんの話はノンパラメトリック回帰の話に繋がるので、興味があるひとは統計学とか計量経済学を履修しよう。
練習問題6 性による差を検証してみる(☆)
仮説では、性別によって滞在時間の分布に差があるはずだった。このことを集計表で確認してみなさい。
©2017, Hiroshi Santa OGAWA
このページにアダルトコンテンツ、XXXコンテンツ類は一切含まれていません。暴力反対.