2006年度経済情報処理
表1(原データ)は、あるグループについて、各メンバーの性別と文系・理系の別を調べたものである。このデータから、「男性と女性では文系・理系の選択に差がある」かどうかをチェックしたい。
表1. 原データ
| 名前 | 性別 | 文系・理系の別 |
|---|---|---|
| 太郎 | 男性 | 文系 |
| 花子 | 女性 | 理系 |
| かな | 女性 | 理系 |
| じん | 男性 | 文系 |
| さくら | 女性 | 文系 |
| 一郎 | 男性 | 理系 |
そこで、縦に文系・理系の別を取り、横に男性・女性の別を取った以下のような表を作成してみる。
| 人数 | 性別 | ||
|---|---|---|---|
| 女性 | 男性 | ||
| コース | 文系 | ① | ② |
| 理系 | ③ | ④ | |
表中①に入るのは「女性」かつ「文系」の人なので、表1をその条件でチェックすると該当するのは{さくら}である。同様に②は「男性」かつ「文系」であるから{太郎、じん}が該当、③は{花子、かな}、④は{一郎}であることがわかる。ここでは個別の名前ではなく人数だけ知りたいので、人数を書き込むと、
| 人数 | 性別 | ||
|---|---|---|---|
| 女性 | 男性 | ||
| コース | 文系 | 1 | 2 |
| 理系 | 2 | 1 | |
となることがわかった。このような表をクロス表と呼ぶ。クロス表を見ると、女性は理系が文系の倍、男性は文系が理系の倍いるので、このグループについては男女でコース選択で差があるように見える(厳密には検定が必要だが、この講義の範囲を超える。興味があれば統計関係の講義を履修すること)。
練習問題 1. 以下のデータ(表2)から縦に居住地、横に性別をとった人数のクロス表を手作業で作成してみなさい
表2. 居住地・性別・年収
| 居住地 | 性別 | 年収(万円) |
|---|---|---|
| 中区 | 女 | 176 |
| 神奈川区 | 女 | 579 |
| 西区 | 女 | 623 |
| 中区 | 女 | 487 |
| 中区 | 男 | 271 |
| 鶴見区 | 男 | 436 |
| 神奈川区 | 男 | 816 |
| 神奈川区 | 男 | 854 |
| 神奈川区 | 女 | 244 |
| 西区 | 女 | 666 |
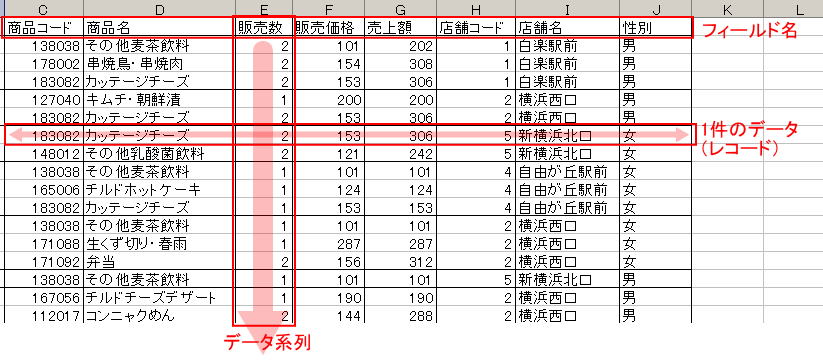
が大前提。たとえば下の図で言えば、E列に入っているデータは全て販売数のデータであって、店舗コードなどが混じっていないことが1の意味になる。また、2は、E列を代表する名前が「販売数」であることを、3は6行目に入っているデータは全て「183082 カッテージチーズ」に関するデータであり、そのほかの行のデータと入り交じっていないことを意味する。
ピボットテーブルはデータをフィールド名で管理するため、フィールド名の名前をどう付けるかは作業効率上重要となる。注意点は以下の通り。
例題1. cvs.xls のシート 売上明細 に入っているデータから、店舗と商品の販売個数に関するクロス表を作る
Step1. ピボットテーブルウィザードを起動する
ピボットテーブルを作成する場合は、[データ(D)]-[ピボットテーブルとピボットテーブルグラフレポート(P)]を選択する
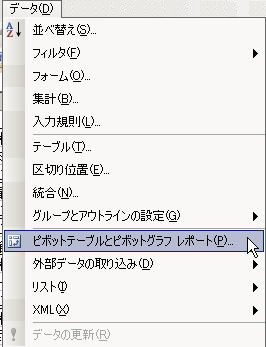
Step2. データのある場所と作成するレポートの種類を指定する
今回は Excelの中に入力済みのデータを用いるので、データのある場所としては「Excelのリスト/データベース(M)」を選択。レポートの種類としては、「ピボットテーブル(T)」を選ぶ
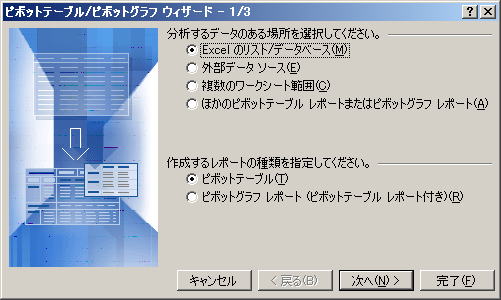
Step3. データの範囲を指定する
Step2.で、Excelの中に入力済みのデータを使うことにしたので、データが入っている範囲をここで指定する。この際、データのフィールド名が入っている行も忘れずに範囲に含めること。具体的にはA1:J34の範囲
Step 4. 作成場所を指定する
既存ワークシートの一部に作成することもできるが、ピボットテーブルは意外に大きくなったりするので新しいワークシートに作成しておいた方が無難。
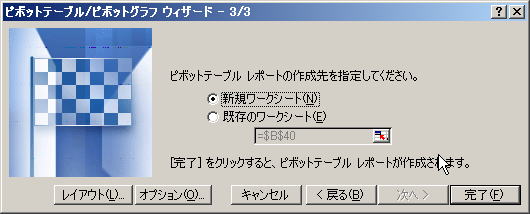
Step 5. 集計に使う縦横の属性フィールドと、集計用のフィールドを指定する
Step4. まで終わると、新しいシートに下のようなクロス表のひな形と、指定した範囲に含まれているフィールドが表示される。
ここで作成したいクロス表は店舗名と商品名が縦横の属性、それぞれの属性ペアを満たす販売数の合計が集計結果となればよいので、
すればよい。
Step 6. できあがり
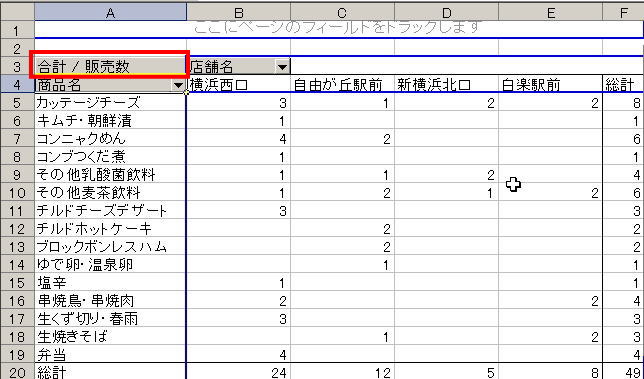
下の図で赤枠を付けた部分(合計/販売数)が、データアイテムが何であり、どのような集計を行ったかを表している。もし他の集計方法をとりたければ、赤枠をつけた部分を右ボタンクリックして表示されるメニューから「フィールドの設定」を選ぶと指定できる。指定できる集計方法は、
となっている。また、オプションを指定することによって縦・横方向の構成割合なども簡単に計算できる。
練習問題2. cvs.xls のデータを使って以下のクロス表を作りなさい
練習問題3. cvs-db.xls のデータを使って以下の作業をしなさい
ただし、
売上伝票 シートに入っているデータは、レシート毎の情報(伝票番号、日付、店舗コード、購入者の性別)
販売明細 シートに入っているデータは、個別商品毎の情報(明細番号、伝票番号、伝票内の順序、商品コード、数量)
店舗マスタ と 商品マスタ は、それぞれ店舗コード、商品コードから店舗名や商品名、価格を得るための表
となっている
※VLOOKUP関数を適宜使うこと。表頭あるいは表側で複数の属性を組み合わせて集計を行う場合は、複数のフィールド名を表頭あるいは表側部分にドロップすればよい。
表3. 日付・店舗・商品別売上一覧(部分)
| 日付 | 店舗コード | 店舗名 | 商品コード | 商品名 | 単価 | 数量 | 売上 |
|---|---|---|---|---|---|---|---|
| 2007/1/5 | 1 | 白楽駅前 | 1300 | 漬け物 | 200 | 1 | 200 |
| 1600 | 寿司 | 1000 | 1 | 1000 | |||
| 2 | 横浜西口 | 1000 | 豆腐 | 105 | 2 | 210 | |
| 1300 | 漬け物 | 200 | 2 | 400 | |||
| 1600 | 寿司 | 1000 | 2 | 2000 | |||
| 1800 | チーズ | 600 | 1 | 600 | |||
| 1900 | お茶 | 150 | 2 | 300 | |||
| 2000 | 炭酸飲料 | 150 | 2 | 300 | |||
| 3 | 渋谷東口 | 1200 | 納豆 | 150 | 1 | 150 | |
| 5 | 新横浜北口 | 1300 | 漬け物 | 200 | 3 | 600 | |
| 1600 | 寿司 | 1000 | 3 | 3000 | |||
| 1900 | お茶 | 150 | 4 | 600 | |||
| 2100 | 酒 | 220 | 4 | 880 | |||
| 2007/1/6 | 1 | 白楽駅前 | 1000 | 豆腐 | 105 | 3 | 315 |
| 1100 | こんにゃく | 98 | 1 | 98 | |||
| 1300 | 漬け物 | 200 | 1 | 200 | |||
| 1600 | 寿司 | 1000 | 1 | 1000 | |||
| 1800 | チーズ | 600 | 2 | 1200 | |||
| 1900 | お茶 | 150 | 3 | 450 | |||
| 2 | 横浜西口 | 1000 | 豆腐 | 105 | 2 | 210 | |
| 1100 | こんにゃく | 98 | 1 | 98 | |||
| 1400 | 煮豆 | 245 | 1 | 245 | |||
| 1500 | 佃煮 | 500 | 1 | 500 | |||
| 1900 | お茶 | 150 | 2 | 300 | |||
| 2000 | 炭酸飲料 | 150 | 2 | 300 | |||
| 2100 | 酒 | 220 | 1 | 220 | |||
| 3 | 渋谷東口 | 1200 | 納豆 | 150 | 1 | 150 | |
| 1500 | 佃煮 | 500 | 2 | 1000 | |||
| 1700 | かまぼこ | 300 | 2 | 600 | |||
| 4 | 自由が丘駅前 | 1700 | かまぼこ | 300 | 2 | 600 | |
| 5 | 新横浜北口 | 1000 | 豆腐 | 105 | 1 | 105 | |
| 1200 | 納豆 | 150 | 2 | 300 |
練習問題4. pivot.xls を使って以下の作業を行いなさい
pivot.xls の 成績 シートに入っているデータは、ある高校での成績データである。内申平均点はこの高校の学区内にある 3つの中学校( A, B, C )での成績(相対評価)を平均したものになっている。科目毎の成績は高校で実施した試験の得点(絶対評価)を示している。
©2006, Hiroshi Santa OGAWA
このページにアダルトコンテンツ、XXXコンテンツ類は一切含まれていません。暴力反対.