2007年度経済情報処理
第3回 データの検索と利用
……保管人は機械に質問するのがわかっていたので、アレーンは現存する何億何千億という記録のなかに、安全に遺言を埋めて残しておいたのだ。連想機が計画的にそれを探せば、かならず見つかるわけだ。
「銀河帝国の崩壊」アーサー・C・クラーク(井上勇 訳)東京創元社 より
第3回の目標
- 図書館の書誌データベースを使って資料を探すことができるようになる
- 官公庁などの統計情報を探して利用できるようになる
- インターネット検索で得られた結果を評価して利用できるようになる
↑経済情報処理(2007)ホームページに戻る
準備問題
1. 「狂牛病とプリオンに関する本で2002年に出たもののタイトルと出版社」を調べてみなさい
2. 「2005年10月1日に12歳だった日本人の数」を調べてみなさい
3. 「キャロライン洋子という芸名でかつて活動していたアイドルの本名」を調べてみなさい
1. 情報検索
リンダールのアレーンの遺言はそれを求める者が計画的に探せば見つかるが、偶然見つかったりはしないように隠されていた。実際、この検索を行った記録保管人ロアデンはその仕事を何万年もやっていたにもかかわらず、リンダールのアレーンという人名すら知らなかった。つまり、データとしては確かに記録の中に存在しても、そのデータを必要とするアルビンが現れ、計画的に検索してはじめて情報としての意味を持ったのである。
情報化社会では、適切な情報を、迅速かつ効率的に入手し、十分に活用することが求められる。インターネットの普及は、使えるデータの量は増やしたかもしれないが、その中から自分の要求を満たす情報を探し出すことはむしろ難しくなっている。そのため、「計画的、戦略的に情報を探す」という技法が要求される。サルのように検索エンジンに思いついたキーワードを入れて、一番上に出てくる項目をクリックして「見つかりました」という方法ではダメ。
2. 情報検索の定義・意義
記録情報を対象とした情報検索は、大きく「主題を検索する」「データ・事実を検索する」の2つに分類できる
- 主題の検索
-
- ある概念(テーマ)について言及しているデータを検索する
- 検索結果として得られるのは、文献リストや文献そのもの、Webページ
- 検索結果と求める情報とは必ずしも一致しない
- 検索結果が求める情報と一致する程度が重要(再現率・精度)
- データ・事実の検索
-
- 経済・経営分野の統計データなどの数値データや電話帳などの事実(ファクト)を検索する
- 検索結果として得られるのは、事実そのもの
- 検索結果は与えた検索条件と完全に一致する
- 「1995年に35歳だった日本人男性の数」という検索で結果が得られたとすれば、条件を満たす人数が得られる
- 検索結果が得られない場合は、不完全に一致した答えが得られるわけではなく、全く得られない
- 求める情報が得られるか否かが重要(得られれば、条件と一致はしているはずだから)
3. 書誌検索
- 通常、図書館などのサービス提供者によって提供され、所蔵している資料を検索する手段を与える
- 単なるタイトルなどの文字列だけではなく、内容に応じて検索用のキーワード(索引語)が付与されていることが多い
- タイトル・著者名などに含まれない主題を検索することができる
- サービス提供者によって統一的な指針で索引語が付与されている→索引語で表される概念を含む資料を漏れなく検索できる
- 索引語には使い方を細かく統制して体系化したシソーラス(thesaurus)が用意されていることもある
例題1 神奈川大学図書館で「狂牛病」と「プリオン」に関する本を探したい
- 多くの図書館ではOPAC(Online Public Access Catalog)と呼ばれるサービスを提供している
- 神奈川大学図書館も、もちろんOPACを提供している
- 日本国内で出版された本は、原理的には全て国会図書館の OPACで検索できるはず
Step 1. http://opaclib.kanagawa-u.ac.jp/ に接続する。正しく接続すれば下のような画面が表示される
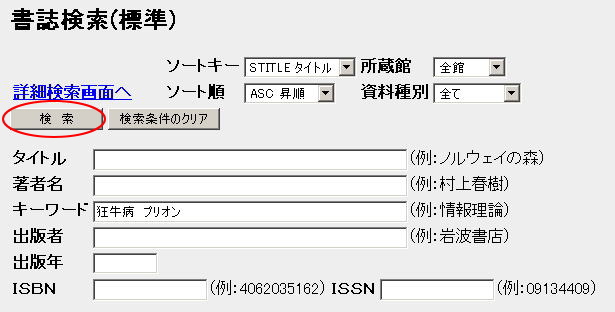
Step 2. 「キーワード」欄に探したいキーワードである「狂牛病」と「プリオン」を入力して、「検索」ボタンをクリックする
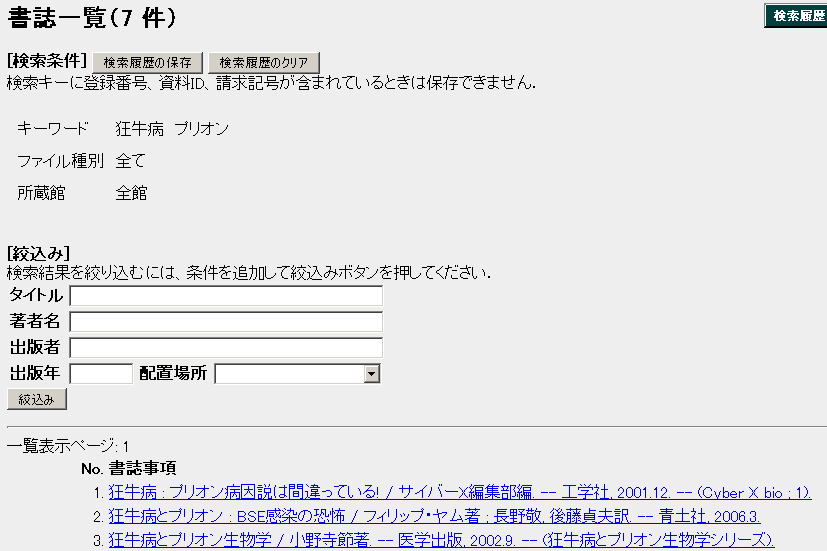
Step 3. 検索結果が表示される。この場合は7件あったことがわかる
練習問題1
神奈川大学図書館が提供しているOPAC(Online Public Access Catalog)には「タイトル」という検索項目と「キーワード」という検索項目がある。タイトルは、タイトルに含まれる語句の検索を行うが、キーワードは図書館で主題に関して付与した索引語のほか、タイトル、著者名、出版者、出版地、件名、キーワード、ID、ファイル種別での検索が可能である。つまり、キーワードで検索するほうがより広い範囲での検索が可能になるはず。以下の語を「タイトル」に入れて検索した場合と「キーワード」に入れて検索した場合で結果がどう違うかを確認しなさい
Tips. 効率よく検索を行う: AND, OR, NOTを使った検索の考え方
Tips. 神奈川大学図書館OPACでの「キーワード」は何を見ているのか
4. 統計の検索
- 説得力のあるレポートや論文を書くためには、基本的なデータは数値でおさえておく必要がある
- しかし、統計データの検索はインターネット検索の苦手とするところ
- たとえば「20代後半男性の完全失業率のうつりかわり」を調べたいときに「20代後半 男性 完全失業率」というキーワードで
googleや yahoo!を使って検索しても、網羅的な統計データは出ない
- しかし、総務省統計局のWebから「労働力調査」を調べれば全部出てくる
- データはできる限りオリジナルの出所に当たる。孫引きはダメ
- 政府統計に関して言えば、総務省統計局が作成している「統計データ・ポータルサイト」がかなり良い入り口
- 官庁ごとに独自のデータ検索システムを用意している場合もあるので、調査官庁が分かれば直接当該官庁のWebを見るのもいい方法
など
練習問題 2.
以下の情報について調べてみなさい
- 2005年10月1日に12歳だった日本人の数
- 2002年の日本の国内総生産(GDP)
- 平成15年の横浜市内耕地総面積(ヘクタール)
5. 商用データベース
- 様々な分野について、専門のデータベースを提供するサービスが商売として成立している
など、権利関係があるため通常インターネット検索では調べられない
- 商用データベースは数が非常に多いため、自分に必要なデータベースをまず探すのが大変
などの、データベースのデータベースを使うとアタリがつけやすい
- 神奈川大学図書館では、様々な商用データベースと契約しており、必要に応じて使うことができる(学内からの利用に限る)
6. インターネット検索
6.1 インターネット検索の基本的な仕組
- googleやYahoo!などの強力な検索サービスにより、キーワードによるWeb上の情報検索は便利かつ広範囲に使えるものになった
- 基本的なシカケとしては、
- クローラ、スパイダーなどと呼ばれる専用プログラムがWebページの中に含まれるリンクをたどり、ページを収集
- 集めたページに含まれる語句を抽出して一覧表を作る
- 検索要求があったときに、検索に使われた語句を含むページを表示する
という大まかなところはどこも大して変わらない。
- しかし、どうやってページを表示する際に順番を決めているかは、実はどこも公開していない
- Googleは PageRankという技術を使っているが、実装は公開されていない
- Yahoo!は Yahoo! Search Technology(YST)という技術を使っているが、これも詳細は公開されていない
- MSNも独自方式でランク付けを行っている。これまた詳細は不明
- しかも、SEO(Search Engine Optimization)という、検索エンジンで上位に表示されるようにWebページを改善するという商売もある
6.2 インターネット検索の強み
- 機械的にページを収集・インデックス作成を行っているため、収録範囲が広い
- 自由なキーワードを指定してページを検索できる→適切なキーワードを使えば、主題検索には便利
- インターフェースが簡単。専用データベースに比べると敷居が低く、誰でも使える
6.3 インターネット検索の問題点
- ページ収集プログラムは、ページに書いてある内容については評価しない。Webで公開されている記事は玉石混淆なので、たまたまヒットしたページに正しいことが書いてある保証は全くない。たとえば、Wikipediaなども自分が詳しい分野をよく読んでみれば「ホントかよ」というような記述はよくある。
- ページ収集プログラムは「リンク」をたどってページを集める→リンクされていないページは収集できない(ディープ・ウェブ)
- 専門的なデータが収録されているデータベースの多くはページ収集プログラムでアクセスできない
- 専門的なデータは、たとえページとして収集できてもキーワードによるインデックス作成がうまくできない
そこを無視していいのか?
- 多くのユーザは、検索結果の先頭数件しか見ないが、求める主題と一致しているかどうかは不明
- キーワードの意味が統制されていないため、いろいろな意味で使われる言葉だと検索結果の解釈が難しい
- 事実・データの検索は難しい
- 検索事業者が恣意的にページを検索対象から落とす事例がある→Web検索がすべてだと思うと大間違い
- 検索エンジン各社は中国では政府の方針に従い検索結果を制限している→中国でやっているなら他でやってない保証がどこにあるか?
- たとえばGoogleはドイツやフランスでもそれぞれの地域の法令に基づきナチス情報や民族差別情報が検索できないようにしている
- 検索事業者は慈善事業をしているわけではない
- 基本的には、検索結果のページに広告を出すことで収益を得ている
- 検索事業者に金を払う「お客様」は広告主であることを常に意識すること
- 金を払わず検索するだけのユーザは客ではない → 商用データベースとは違う
- 新聞や雑誌でも、大口広告主をあからさまに批判するような記事は載せない
- 下の表はグーグルとヤフーの損益計算書から抜き出した売り上げと純利益。これだけのビッグビジネスに成長している以上、広告主に対して配慮するのはむしろ当然
グーグルと米ヤフーの第1四半期業績(単位:米ドル)
| 企業名 |
売上高 |
純利益(税引き後) |
| 2007年 1〜3月 |
2006年 1〜3月 |
2005年 1〜3月 |
2007年 1〜3月 |
2006年 1〜3月 |
2005年 1〜3月 |
| グーグル |
$3,663,971,000 |
$2,254,755,000 |
$1,256,516,000 |
$1,002,162,000 |
$592,291,000 |
$369,193,000 |
| ヤフー |
$1,671,850,000 |
$1,567,055,000 |
$1,173,742,000 |
$142,424,000 |
$159,859,000 |
$204,560,000 |
| (参考) |
2006年10〜12月 |
2005年10〜12月 |
|
2006年10〜12月 |
2005年10〜12月 |
|
| トヨタ(連結) |
$51,221,533,000 |
$44,444,891,000 |
|
$3,556,425,000 |
$3,313,116,000 |
|
資料出所: 各社の損益計算書、トヨタの金額は、$1=120円で換算したもの
コラム: キャロライン洋子の本名は?
キャロライン洋子は1960年代〜1970年代にかけて子役として活動していた人なので、そもそも存在を知っていること自体がおじさん・おばさんの証拠なのだが、ふと「そういえば、キャロライン洋子って今はなにやってるんだ?」と疑問におもった。とりあえずインターネット検索を掛けてみると、こんな記述が見つかった。
「キャロライン洋子(本名カフ・C・ナーン)は上智大学卒業後、1981年にオレゴン州立大コンピューター学科・同大学院首席卒業し、現在はヒューレット・バッカード社のAI開発指導部でソフトの研究開発のお偉いさん」
へーっと思ったのだが、他の検索結果も一応見てみると …… どれもほとんど同じことが書いてある。どれがオリジナルかはもう分からないけど、どうやらみんなで引き写しあった感じ。みんなでコピーしているとしたら、情報の信憑性はかなり怪しい。(続きを読む…)
Tips. Web検索で出てきた情報をチェックする
練習問題3
Web検索サービス(Yahoo!, Google, MSNサーチ, gooなど)の少なくとも2つ以上を使って以下のことがらについて調べてみなさい
- 映画「フラッシュ・ゴードン」のテーマ曲を演奏していたグループ名
- MNSネットワークでの個人使用領域の確認方法
- google八分
- 1995〜2004年の25〜29歳男性の完全失業率(年平均)
↑経済情報処理(2007)ホームページに戻る
©2007, Hiroshi Santa OGAWA
このページにアダルトコンテンツ、XXXコンテンツ類は一切含まれていません。暴力反対.