2006年度経済情報処理
第3回 情報の検索と利用
- 情報化社会では
- 適切な情報を
- 迅速かつ効率的に入手し
- 十分に活用すること
が求められる
- 自分の要求を満たすものが「情報」
- インターネットの普及は、使える「データ」の総量は増やしたが、「情報」を探し出すのは逆に難しくなった
- Yahoo!や Googleに代表される検索エンジンの特徴と限界を知ることは重要
- いたずらに検索を繰り返すより、戦略的な情報検索を行う
↑経済情報処理(2006)ホームページに戻る
3.1 情報とは何か
- ここでは「情報」を人間の知的活動に影響を与える刺激と定義する
- 単なる事実の記述などは、適切に利用できなければ「情報」とは考えない
- 図書館にある本も、適切なものを見いだすことができて初めて「情報」になると考える
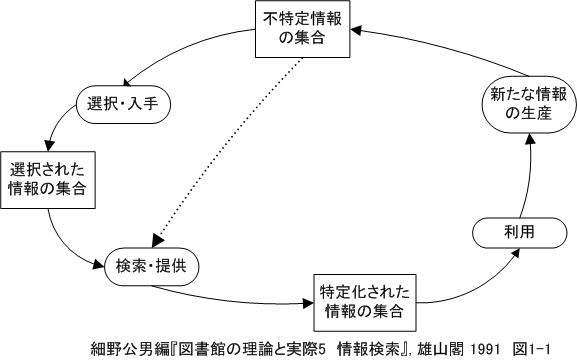
上の図で言えば、「不特定情報の集合」の代表がインターネットで公開されている多種多様なデータであり、「選択された情報の集合」の代表は日経テレコンなどの商用データベースと考えられる。
- 情報ではないデータの例
- 過去1年分の新聞が単に積み上げられている山
- 情報として使えるデータの例
- 過去1年分の新聞から、興味がある記事を切り抜いて整理したスクラップブック
3.2 情報検索の定義・意義
知的活動のためには必要な情報を
することが重要。「経済情報処理」では、このプロセスを全部カバーする。
記録情報を対象とした情報検索は、大きく「主題を検索する」「データ・事実を検索する」の2つに分類できる
- 主題の検索
-
- ある概念(テーマ)について言及しているデータを検索する
- 検索結果として得られるのは、文献リストや文献そのもの、Webページ
- 検索結果と求める情報とは必ずしも一致しない
- 検索結果が求める情報と一致する程度が重要(再現率・精度)
- データ・事実の検索
-
- 経済・経営分野の統計データなどの数値データや電話帳などの事実(ファクト)を検索する
- 検索結果として得られるのは、事実そのもの
- 検索結果は与えた検索条件と完全に一致する
- 「1995年に35歳だった日本人男性の数」という検索で結果が得られたとすれば、条件を満たす人数が得られる
- 検索結果が得られない場合は、不完全に一致した答えが得られるわけではなく、全く得られない
- 求める情報が得られるか否かが重要(得られれば、条件と一致はしているはずだから)
3.3 書誌検索
- 通常、図書館などのサービス提供者によって提供され、所蔵している資料を検索する手段を与える
- 単なるタイトルなどの文字列だけではなく、内容に応じて検索用のキーワード(索引語)が付与されていることが多い
- タイトル・著者名などに含まれない主題を検索することができる
- サービス提供者によって統一的な指針で索引語が付与されている→索引語で表される概念を含む資料を漏れなく検索できる
- 索引語には使い方を細かく統制して体系化したシソーラス(thesaurus)が用意されていることもある
例題1 神奈川大学図書館で「情報検索」に関する本を探したい
- 多くの図書館ではOPAC(Online Public Access Catalog)と呼ばれるサービスを提供している
- 神奈川大学図書館も、もちろんOPACを提供している
Step 1. http://opaclib.kanagawa-u.ac.jp/ に接続する。正しく接続すれば下のような画面が表示される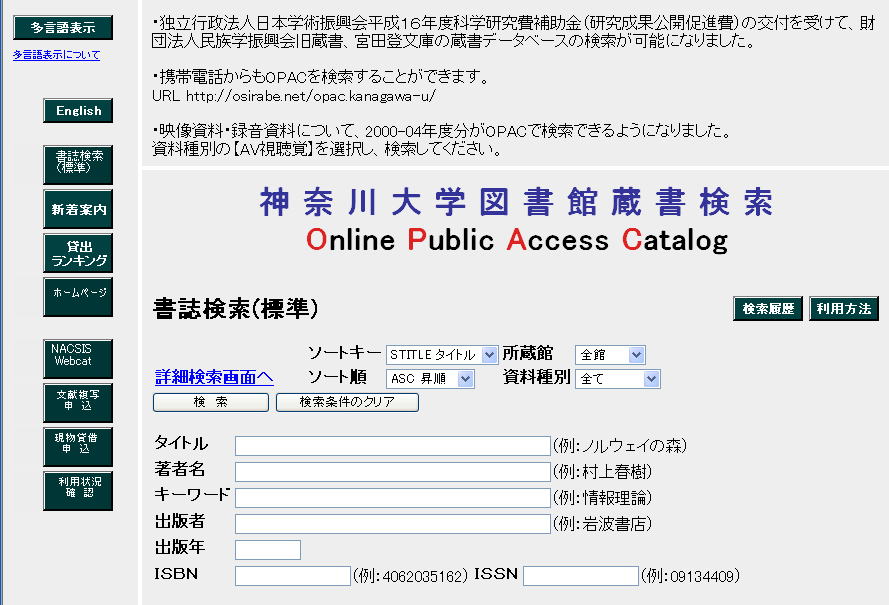
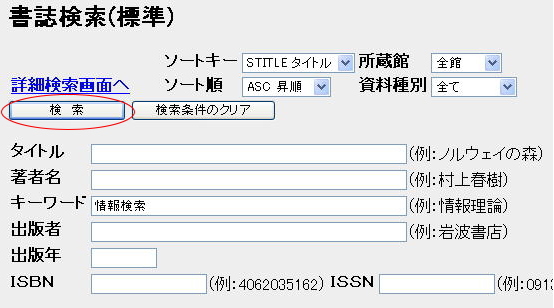
Step 2. 「キーワード」欄に探したいキーワードである「情報検索」を入力して、「検索」ボタンをクリックする
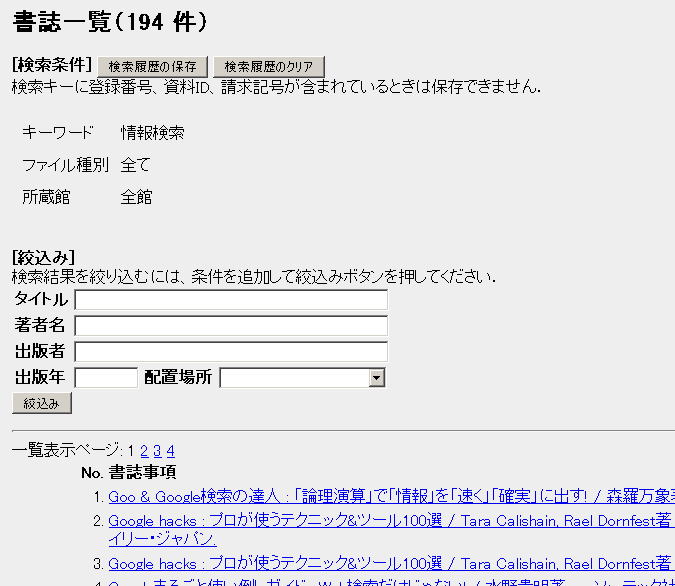
Step 3. 検索結果が表示される。この場合は194件あったことがわかる
練習問題3.1
神奈川大学図書館が提供しているOPAC(Online Public Access Catalog)には「タイトル」という検索項目と「キーワード」という検索項目がある。タイトルは、タイトルに含まれる語句の検索を行うが、キーワードは図書館で主題に関して付与した索引語のほか、タイトル、著者名、出版者、出版地、件名、キーワード、ID、ファイル種別での検索が可能である。つまり、キーワードで検索するほうがより広い範囲での検索が可能になるはず。以下の語を「タイトル」に入れて検索した場合と「キーワード」に入れて検索した場合で結果がどう違うかを確認しなさい
Tips. 効率よく検索を行う: AND, OR, NOTを使った検索の考え方
Tips. 神奈川大学図書館OPACでの「キーワード」は何を見ているのか
3.4 商用データベース
- 様々な分野について、専門のデータベースを提供するサービスが商売として成立している
など、権利関係があるため通常インターネット検索では調べられない
- 商用データベースは数が非常に多いため、自分に必要なデータベースをまず探すのが大変
などの、データベースのデータベースを使うとアタリがつけやすい
- 神奈川大学図書館では、様々な商用データベースと契約しており、必要に応じて使うことができる
練習問題3.2
以下の情報を調べたい。何を使ってどのように調べるといいか考えなさい
- 新聞・雑誌で「少子化」が話題になってきたのはいつ頃からかを知りたい
- 横浜市神奈川区にある小学校の住所と連絡先を調べたい
- 「GBIC」がどういうものかを知りたい
3.5 インターネット検索
3.5.1 インターネット検索の基本的な仕組
- googleやYahoo!などの強力な検索サービスにより、キーワードによるWeb上の情報検索は便利かつ広範囲に使えるものになった
- 基本的なシカケとしては、
- クローラ、スパイダーなどと呼ばれる専用プログラムがWebページの中に含まれるリンクをたどり、ページを収集
- 集めたページに含まれる語句を抽出して一覧表を作る
- 検索要求があったときに、検索に使われた語句を含むページを表示する
という大まかなところはどこも大して変わらない。
- しかし、どうやってページを表示する際に順番を決めているかは、実はどこも公開していない
- Googleは PageRankという技術を使っているが、実装は公開されていない
- Yahoo!は Yahoo! Search Technology(YST)という技術を使っているが、これも詳細は公開されていない
- MSNも独自方式でランク付けを行っている。これまた詳細は不明
- しかも、SEO(Search Engine Optimization)という、検索エンジンで上位に表示されるようにWebページを改善するという商売もある
3.5.2 インターネット検索の強み
- 機械的にページを収集・インデックス作成を行っているため、収録範囲が広い
- 自由なキーワードを指定してページを検索できる→適切なキーワードを使えば、主題検索には便利
- インターフェースが簡単。専用データベースに比べると敷居が低く、誰でも使える
3.5.3 インターネット検索の問題点
- ページ収集プログラムは「リンク」をたどってページを集める→リンクされていないページは収集できない(ディープ・ウェブ)
- 専門的なデータが収録されているデータベースの多くはページ収集プログラムでアクセスできない
- 専門的なデータは、たとえページとして収集できてもキーワードによるインデックス作成がうまくできない
そこを無視していいのか?
- 内容については無保証。Webで公開されている内容は玉石混淆なので、たまたまヒットしたページに正しいことが書いてある保証は全くない
- 多くのユーザは、検索結果の先頭数件しか見ないが、求める主題と一致しているかどうかは不明
- キーワードの意味が統制されていないため、いろいろな意味で使われる言葉だと検索結果の解釈が難しい
- 事実・データの検索は難しい
- 検索事業者が恣意的にページを検索対象から落とす事例がある→Web検索がすべてだと思うと大間違い
- 検索エンジン各社は中国では政府の方針に従い検索結果を制限している→中国でやっているなら他でやってない保証がどこにあるか?
- たとえばGoogleはドイツやフランスでもそれぞれの地域の法令に基づきナチス情報や民族差別情報が検索できないようにしている
- 検索事業者は慈善事業をしているわけではない
- 基本的には、検索結果のページに広告を出すことで収益を得ている
- 検索事業者に金を払う「お客様」は広告主であることを常に意識すること
- 金を払わず検索するだけのユーザは客ではない → 商用データベースとは違う
- 新聞や雑誌でも、大口広告主をあからさまに批判するような記事は載せない
- 下の表はグーグルとヤフーの損益計算書から抜き出した売り上げと純利益。これだけのビッグビジネスに成長している以上、広告主に対して配慮するのはむしろ当然
グーグルと米ヤフーの第1四半期業績(単位:米ドル)
| 企業名 |
売上高 |
純利益(税引き後) |
| 2006年 1〜3月 |
2005年 1〜3月 |
2006年 1〜3月 |
2005年 1〜3月 |
| グーグル |
$2,254,755,000 |
$1,256,516,000 |
$592,291,000 |
$369,193,000 |
| ヤフー |
$1,567,055,000 |
$1,173,742,000 |
$159,859,000 |
$204,560,000 |
資料出所: 各社の損益計算書
コラム: キャロライン洋子の本名は?
キャロライン洋子は1960年代〜1970年代にかけて子役として活動していた人なので、そもそも存在を知っていること自体がおじさん・おばさんの証拠なのだが、ふと「そういえば、キャロライン洋子って今はなにやってるんだ?」と疑問におもった。とりあえずインターネット検索を掛けてみると、こんな記述が見つかった。
「キャロライン洋子(本名カフ・C・ナーン)は上智大学卒業後、1981年にオレゴン州立大コンピューター学科・同大学院首席卒業し、現在はヒューレット・バッカード社のAI開発指導部でソフトの研究開発のお偉いさん」
へーっと思ったのだが、他の検索結果も一応見てみると …… どれもほとんど同じことが書いてある。どれがオリジナルかはもう分からないけど、どうやらみんなで引き写しあった感じ。みんなでコピーしているとしたら、情報の信憑性はかなり怪しい。
そこで、「オレゴン州立大学コンピュータ学科」という情報からオレゴン州立大学の公式webを検索してみる。ふむ。Koff, Caroline N.という人がM.S. in Computer Scienceを 1988年に取ったという記述は見つかった。これは大学の公式サイトの情報だから、自分のところの卒業生に関してはそう大きな嘘はないだろう。あれ? 年が違う。「1981年に卒業した」のに1988年に修士取ったの? 他の情報から生年月日を調べてみると、複数のソースから
1962年生まれらしいとわかった。1981年だとまだ 19歳。日本で上智大学卒業後にオレゴン州立大学行ったなら、
19歳で M. S. 取ったというのはちょっと信じにくいので、1988年が本当なんだろう。ちなみに、上智大学のWebからはキャロライン洋子も
Koffも見つからなかったので、上智を卒業したという情報も真偽のほどは確かでない。
オレゴン州立大学の情報と食い違う点は本名にもある。大学の情報だと姓が Koff、ファーストネームがCaroline、ミドルネームが N. となっているけど、日本語の情報だと、ナーンが姓、ファーストネームがカフ、ミドルネームが C.になっている。更に調べると、オレゴン州立大学に居た人の N.は Nanということまでわかった。ひょっとして、 Koff, Caroline Nan と書いてあったのを、","を無視して解釈したのか? 確かに西洋人は ファーストネーム ミドルネーム ラストネーム という順序で名前を書くことが多いけど、文献参照などでは姓を最初に持ってきてその後に
","を入れるという記法もよく使われる。といっても論文などで参考文献を見慣れてない人にはあまり知られてない可能性が高いので
Koff, Caroline Nanを誤読した結果「カフ・C・ナーン」になってしまったのか? このへんでWeb検索では無理っぽくなってきたので、検索対象を特許データベースやnetnewsにまで広げる。1980年代のCSの院生が
netnewsにポストしたことがないなんて信じられないし、メーカーの技術者で偉い人が特許の1本も出してないわけがないからね。すると、オレゴンにいたKoffさんは、確かに大学院のときは
AIの研究をしていて、日本語とのバイリンガルで、HP社に入社して、HPから特許を出願したことがあることまで分かった。
ここまでの調査で、キャロライン洋子の本名と大学卒業年について怪しいことが分かった。こういう基本情報が間違っていると、本当に首席卒業でヒューレットパッカード社でAIの偉い人なのかどうかも疑わしい。卒業年と本名が間違ってるということは、首席という情報も原資料に当たってないことは確かだし、HP内でのポジションもちゃんと調べたとは思えない。そもそも、Koffさんとキャロライン洋子が同一人物であるという確たる証拠は見つからなかった。何分にも古い話なので、インターネット上の情報では厳しいかな。ということでこんどは書誌データベースを検索してみる。すると、1986年に出版された「黒い瞳と星条旗」というキャロライン洋子の本の第1章は「オレゴンだより」と分かったので、キャロライン洋子がオレゴンに行ったことまでは多分本当なのだろう。
「黒い瞳と星条旗」は古い本なので既に絶版。しかし図書館には持っているところもあったので相互貸借サービスで借りてきてみた。するといろいろ面白いことがわかった。特にこの本が有益だったのは、オレゴンからHPに行った
Koffさんがキャロライン洋子と同一人物であることがほぼ確認できた点。同じ時期に同じ学科で同じ分野を研究している同姓同名の人が二人以上いるというケースでなければ、キャロライン洋子がHPに行ったという経路は確認できたと見ていいだろう。本から分かったことを整理すると、以下のようになる。
- キャロライン洋子の last nameはカフ、first nameはキャロライン
- キャロライン洋子はオレゴン州立大学で Computer Scienceを学び、大学院で AIを勉強していた
- オレゴン州立大学に入学したのは1981年、大学院に進学したのが1986年
- キャロライン洋子は上智大学に入学したが、1年間心理学を学んだだけでやめている(卒業していない)
ここで、もう一度 web検索で出てきた情報をチェック。「キャロライン洋子(本名カフ・C・ナーン)は上智大学卒業後、1981年にオレゴン州立大コンピューター学科・同大学院首席卒業し、現在はヒューレット・バッカード社のAI開発指導部でソフトの研究開発のお偉いさん」。もうメタメタですね。
同じフォーマットでここまで分かった情報を情報を書くとこんな感じか? 「キャロライン洋子(本名キャロライン・ナーン・カフ)は上智大学を1年で中退し
1981年にオレゴン州立大学に入学。コンピュータサイエンスを専攻。修士論文を1988年5月に提出して
M. S. in Computer Scienceを取得。卒業時に首席だったかどうかは不明。同年8月のAI関係の学会で報告しているが、そのときは
HPの人として報告しており、特許もHPの人として出したものがあるので HPに入社してしばらく在籍したことは確か。ただし、現在AI開発指導部のお偉いさんかどうかは確認できていない」
一連の裏取り調査で分かったことは、誰かがもっともらしい嘘(あるいは錯誤)を書くと、それがそのまま大量に引き写されて考えナシな検索エンジンによって提供されるという構造が確実に存在するということ。みんな悪気はないのかもしれないけど、裏を取る手間を掛けずに無責任にコピペしてる姿が浮き彫りになった。
Tips. Web検索で出てきた情報をチェックする
練習問題3.3
Web検索サービス(Yahoo!, Google, MSNサーチ, gooなど)の少なくとも2つ以上を使って以下のことがらについて調べてみなさい
- 映画「フラッシュ・ゴードン」のテーマ曲を演奏していたグループ名
- MNSネットワークでの個人使用領域の確認方法
- google八分
- 1995〜2004年の25〜29歳男性の完全失業率(年平均)
3.6 統計の検索
- 説得力のあるレポートや論文を書くためには、基本的なデータは数値でおさえておく必要がある
- しかし、統計データの検索はインターネット検索の苦手とするところ
- たとえば「20代後半 男性 完全失業率」というキーワードで googleや yahoo!を使って検索しても、網羅的な統計データは出ない
- しかし、総務省統計局のWebから「労働力調査」を調べれば全部出てくる
- データはできる限りオリジナルの出所に当たる。孫引きはダメ
- 政府統計に関して言えば、総務省統計局が作成している「統計データ・ポータルサイト」がかなり良い入り口
- 官庁ごとに独自のデータ検索システムを用意している場合もあるので、調査官庁が分かれば直接当該官庁のWebを見るのもいい方法
など
練習問題3.4
以下の情報について調べてみなさい
- 2000年10月1日に12歳だった日本人の数
- 2002年の日本の国内総生産(GDP)
- 平成15年の横浜市内耕地総面積(ヘクタール)
↑経済情報処理(2006)ホームページに戻る
©2006, Hiroshi Santa OGAWA
このページにアダルトコンテンツ、XXXコンテンツ類は一切含まれていません。暴力反対.